
Talking about RAFT and BFT-RAFT.
NON-BFT RAFT
The Raft consensus algorithm was designed from the ground up to be easy to understand and is similar in spirit in many ways to existing consensus algorithms (most notable Paxos & Viewstamped replication), but it stressesd the point on replicating a transaction log rather that a single bit.
Raft had the following features :
-
Strong Leader :
Raft uses a strong leadership form. Log entries only flow from the leader to other servers, thus simplyfying the management of the replicated log. -
Leader election:
Raft introduced randomized timers for more efficient election of leaders. -
Membership changes:
Raft’s mechanism for changing the set of server in the cluster uses a new ‘joint consensus’ approach where the majorities of two different configuratiuons overlap during transitions (membership changes refers to the adding or removing of nodes in a cluster). -
Formal Verification:
Coq has been used to formally proven the safety guarantees of the Raft protocol.
Coq is a formal verification tool used for writing mathematical definitions, algorithms, and theorems, along with their proofs, in a precise and machine-checkable format. It is an interactive theorem prover that allows developers and mathematicians to work with highly reliable code and proof. A paper by Doug Woos et al.(2016) is a significant work in the field of formal verification applied to distributed systems, particularly focused on the Raft consensus protocol, which hence became recognized for its understandability and practicality in ensuring consistency across distributed systems.
The most common paradigm when trying to implement distributed consensus is that of the Replicated State Machine aka SMR, where a ‘deterministic’ state machine is replicated across a set of processes. The state machine is driven by a list of inputs , known as transactions, where each transaction may or may not , depending on its validity, provoke a state transaction and return a result. A transaction is hence an atomic tranasaction on a database, which means it eiher completes or does not.
The job of a consensus protocol, whether in non-BFT or BFT environments, is to be responsible for the ordering of the transactions so that the resulting transaction log is replicated exactly by every process and to keep this replicated log consistent.
Using a deterministic state transition function implies that every process will compute the same state given the same transaction log.
In short :
- Replicated State Machines are typically implemented using a replicated log.
- Each server stores a log containing a series of commands , which the server state machine executes in order.
- Each log containing the same commands in the same order, so each state machine processes the same sequence of commands.
- Since the state machine are deterministic, each computes the same state and the same sequence of outputs.
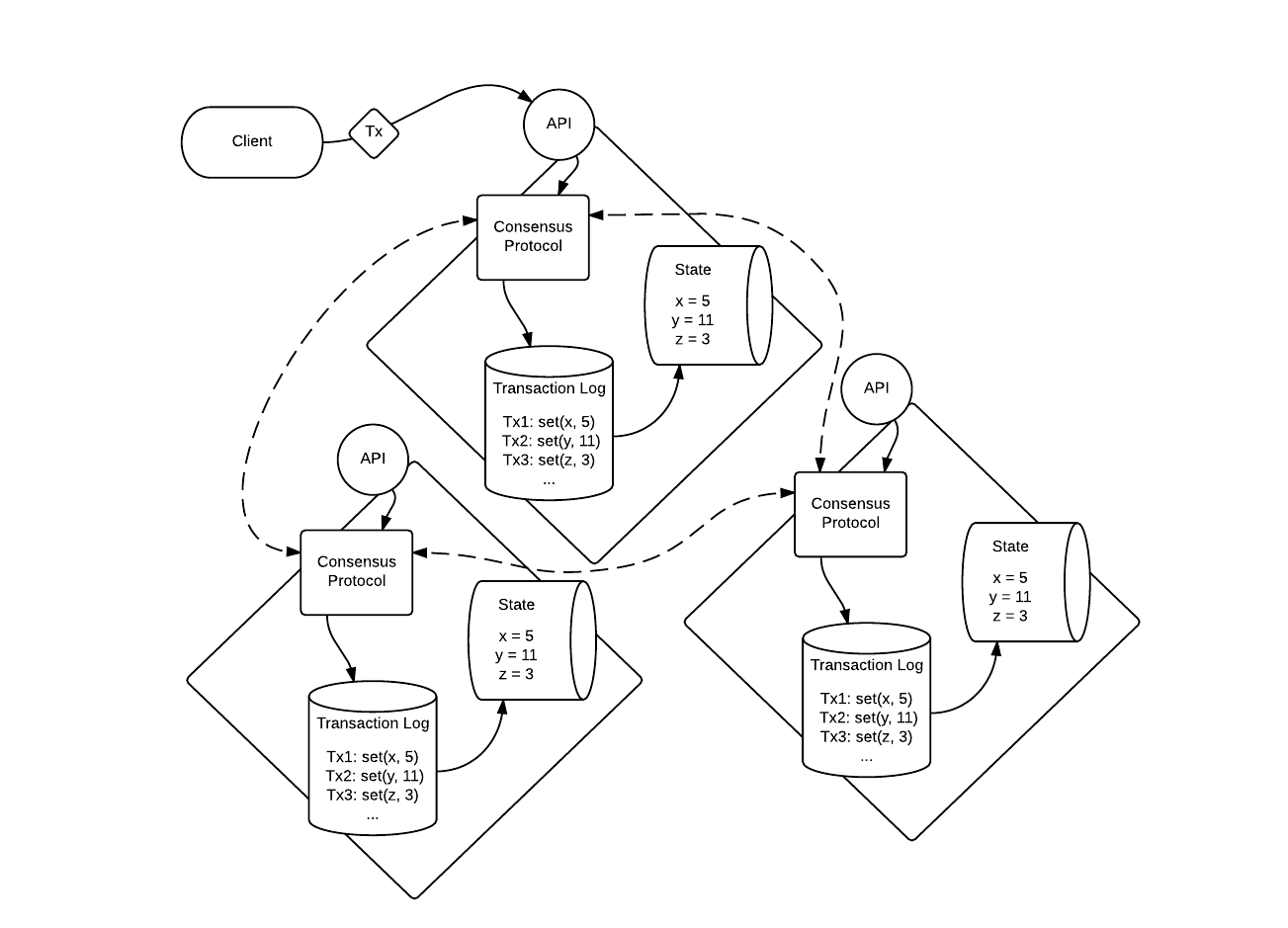
(In the above diagram, each quadrilateral represents a single machine where dashed lines representing communication between machines to carry out the consensus protocol for ordering transactions).
In the case of Raft as eluded earlier, the protocol implements consensus by first electing a distinguished leader , then giving this elected leader complete responsabiltiy for the management of the replicated log. The leader , then accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply log entries to their state machine. A leader can fail or become disconnected from other servers, in which case , a new leader is elected .
Basics of Raft :
At any given time, each server/node is in one of those 3 states : -follower, -candidate, -leader.
In normal operations, there is exactly one leader and all of the other nodes are passive followers. Followers issue no requests on their own but respond solely to request from leader and from election candidates. The leader handles all client requests (if a client contacts a follower, the follower re-directs it to the known leader)
Raft servers communicates via Remote Procedure Calls, and the consensus algorithm only requires 2 main RPCs:
- a RequestVote RPC initiated by candidate to leadership during election cycles.
- an AppendEntries RPC initiated by the leader to replicate log entries .
If you read the extended version of the Ousterhout/Ongaro paper , you will find a 3rd one , InstallSnapshot RPC , which is not essential to the core algorithm but serves as an optimization technique designed to bring a follower’s state up-to-date when it is lagging behind the leader.
Election of the Leader in a Raft cluster
Time is divided into terms, and in each term , one node may be elected as the leader of the cluster.
An election cycle is spawned when a follower node receive no communication from the current leader within a certain time frame
known as ‘election timeout’.
When the election timeout reaches its end, the follower :
- increments its current term,
- transitions to a candidate state,
- votes for itself to become leader,
- sends a RequestVote RPC to all other nodes to gather votes to become leader in the next term.
This timeframe known as ‘election timeout’ is the result of a randomized computation and is done to avoid split votes or a situation where many nodes concurrently believe the leader is down and thus attempt to become leader themselves. In various Raft implementation coded in Golang, this timeout randomization can be done via the crypto/rand library.
Raft assumes that nodes failures are only due to crashing or stopping .
But as I wrote in an earlier post, malicious attacks can cause faulty nodes to exhibit byzantine behavior and thus
tampering with the correctness and safety guarantees of the Raft algorithm.
In order to tackle this issue , some Haskell programmers created a BFT variant of Raft that they named ‘Tangaroa’ aka BFT-Raft.
BFT-RAFT
Those 2 programmers enhanced the default Raft design with additional features:
-
- Message signatures:
BFT-Raft uses digital signatures to authenticate messages and verify their integrity.
For instance, the leader replicates client messages along with client signatures.
This prevents a byzantine leader to modify the content of the message or forgery of the message.
Client public keys are kept separate from replica public keys to enfore that only clients can send new valid commands and that only replica nodes
can send valid RPCs.
- Message signatures:
BFT-Raft uses digital signatures to authenticate messages and verify their integrity.
For instance, the leader replicates client messages along with client signatures.
This prevents a byzantine leader to modify the content of the message or forgery of the message.
Client public keys are kept separate from replica public keys to enfore that only clients can send new valid commands and that only replica nodes
can send valid RPCs.
-
- Client Intervention:
Contrary to original Raft, BFT-Raft lets clients interupt the current leadership if it fails to make progress in the consensus,
thus preventing Byzantine leaders to starve the system.
- Client Intervention:
Contrary to original Raft, BFT-Raft lets clients interupt the current leadership if it fails to make progress in the consensus,
thus preventing Byzantine leaders to starve the system.
-
- Incremental Hashing:
Each replica node in BFT-Raft computes a cryptographic hash every time it appends a new log entry.
The hash is computed over the previous hash and newly appended log entry. A node can sign its last hash to prove that it has replicated the entire log and other servers can verify this quickly using the signature and the hash. This chained structure where each hash incorporates with the previous one can make you think of a typical Merkle Tree but the latter offers more complex verification capabilities.
- Incremental Hashing:
Each replica node in BFT-Raft computes a cryptographic hash every time it appends a new log entry.
-
- ElectionVerification:
Once a node has become leader, its first AppendEntries RPC to each other node will contain a majority of RequestVoteResponse RPCs
that it received in order to become leader (this is sent before the leader received any new entries from clients). Nodes first verify that the leader has actually
won an election by counting and validating each of these RequestVoteResponses. Subsequent AppendEntriesRPCs in the same term to the same node need not include these votes, but a node can ask for them in its AppendEntries Response if necessary.
This will happen if the replica restarted and no longer believes that the current leader won the election for that term.
- ElectionVerification:
Once a node has become leader, its first AppendEntries RPC to each other node will contain a majority of RequestVoteResponse RPCs
that it received in order to become leader (this is sent before the leader received any new entries from clients). Nodes first verify that the leader has actually
won an election by counting and validating each of these RequestVoteResponses. Subsequent AppendEntriesRPCs in the same term to the same node need not include these votes, but a node can ask for them in its AppendEntries Response if necessary.
This will happen if the replica restarted and no longer believes that the current leader won the election for that term.
-
- Commit Verification:
In order to securely commit entries as they are replicated, each AppendEntries Response RPC is broadcast to each other node,
, rather than to the leader. What' s more, each node decides for itself when to increment its commit index, rather than the leader.
This is done by keeping track of the AppendEntries Response RPCs received from the other nodes , which are signed and include the incremental hash
of the last entry in that node' s log. Once a node has received a majority of matching AppenEntriesResponse RPCs from other nodes
at a particular index, it considers that to be the new commit index, and discards any stored AppendEntries Response RPCs for previous indices.
- Commit Verification:
In order to securely commit entries as they are replicated, each AppendEntries Response RPC is broadcast to each other node,
, rather than to the leader. What' s more, each node decides for itself when to increment its commit index, rather than the leader.
This is done by keeping track of the AppendEntries Response RPCs received from the other nodes , which are signed and include the incremental hash
of the last entry in that node' s log. Once a node has received a majority of matching AppenEntriesResponse RPCs from other nodes
at a particular index, it considers that to be the new commit index, and discards any stored AppendEntries Response RPCs for previous indices.
-
- Lazy Voting :
Purpose: preventing unnecessary elections.
Mechanism of action: A node only grants approval(votes) for a leader if it has not heard from the leader recently (inside the timeframe of the current term) or if it receives a message for a client or another node indicating a potential leader change.
- Lazy Voting :